Você usa Stata? Veja como a BD facilita sua análise de dados
Confira como acessar mais de 80 bases de dados públicos de maneira mais prática com nosso pacote em Stata.

TL;DR
Neste artigo vamos explicar como usar o pacote basedosdados no Stata para acessar e explorar diversas bases de dados públicas já tratadas e prontas para análise. No tutorial, você vai entender como instalar e utilizar o pacote em Stata da Base dos Dados, além de conferir um exemplo de análise feito com essa ferramenta.
Sobre o pacote
O novo pacote basedosdados no Stata possibilita o acesso a centenas de tabelas tratadas e compatibilizadas, disponíveis no datalake público da Base dos Dados. O pacote é habilitado para 7 comandos. Os comandos dão desde a possibilidade de listar todos os conjuntos de dados disponíveis do datalake, até baixá-los ou analisá-los diretamente do Stata.
É importante ressaltar que essa versão inicial ainda é um wrapper do pacote do Python e, portanto, necessita da execução de alguns passos antes da utilização. Neste tutorial, mostramos como instalar o Python e autorizar seu projeto do Google — requerimentos obrigatórios para uso do pacote do Stata.
Um wrapper é, basicamente, o aproveitamento da estrutura de um pacote desenvolvido inicialmente em um software, mas adaptado a um software diferente, através de uma ponte que liga esses dois. No caso do Python e do Stata, a ponte é o próprio pacote python no Stata. O motivo do pacote no Stata ainda ser um wrapper é que não há (ou não descobrimos até agora) uma ponte direta entre o Stata e o Big Query, caso contrário do que ocorre no R e no Python.
Na verdade, a única ponte existente até agora no Stata, que permitiria o pacote ser construído inteiramente nessa linguagem, seria através do PostgreSQL. O PostgreSQL também é um banco de dados, assim como o BigQuery. No entanto, isso demandaria mover toda estrutura da Base dos Dados que já está no BigQuery para este novo banco, custo infelizmente alto comparado a manter o pacote do Stata como um wrapper. Por outro lado, o pacote ainda está em desenvolvimento e esta é uma questão em aberto.
Portanto, se você é um stateiro que tem novas ideias ou alguma solução para a questão citada, queremos te ouvir! Faça parte da sala do Discord sobre o pacote.
Como instalar?
Requerimentos
Antes de instalar o pacote basedosdados no Stata, você deve executar dois passos:
-
Garantir que seu Stata seja a versão 16+
-
Garantir que o Python esteja instalado no seu computador — você pode se guiar pelo nosso Mini Tutorial de Python aqui. Nesse tutorial você também vai descobrir como autenticar seu projeto pelo prompt do seu computador (importante!).
Caso esteja utilizando os dados da BD pela primeira vez, é necessário criar um projeto para que você possa fazer as queries no nosso repositório. Ter um projeto é de graça e basta ter uma conta Google (seu gmail por exemplo). Veja aqui como criar um projeto no Google Cloud.
Após garantir esses dois requerimentos obrigatórios, você pode finalmente instalar o pacote digitando o seguinte comando no seu Stata:
- Porque instalar o Python é necessário?
Nossa futura meta é garantir que o pacote tenha sua dependência no próprio Stata. Porém, essa primeira versão ainda é um wrapper do pacote do Python. Por outro lado, isso não significa que você precisa saber Python para usá-lo, pelo contrário. Seguindo os passos abaixo, não será necessário nem abrir o software para configurar o pacote do Stata.
Passo a passo
- Instalando o Python
Clique aqui na opção “Download Python” para baixar o Python. Em seguida, siga as instruções da tela e, principalmente, não esqueça de marcar a opção “add to path”:
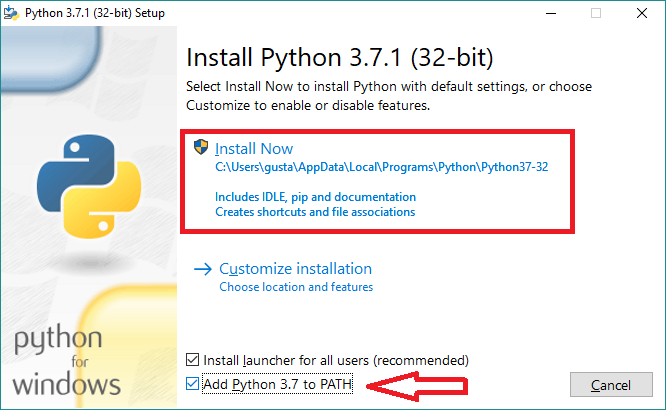
-
Instalando o pacote: configurações iniciais
-
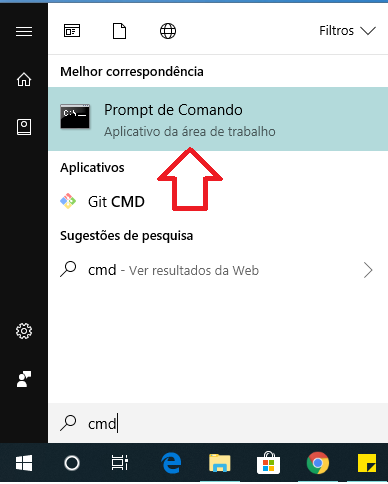
passo: Após instalar o Python, abra o menu iniciar, digite
cmde abra. -
passo: Na tela do
Prompt de Comandoque aparecerá, digitepip install basedosdados -Ue dê enter.
- Após concluir a instalação do pacote basedosdados, digite basedosdados reauth no Prompt de Comando. Copie o link que aparecerá, cole na sua aba de navegação e dê autorização ao google. Em seguida, copie o código gerado, volte e cole na tela do Prompt e dê enter.
Caso esteja utilizando os dados da BD pela primeira vez, é necessário criar um projeto para que você possa fazer as queries no nosso repositório. Ter um projeto é de graça e basta ter uma conta Google (seu gmail por exemplo). Veja aqui como criar um projeto no Google Cloud.
Após finalizar esses 3 passos, já será possível abrir o Stata e começar a usar o pacote. Para saber mais sobre os comandos do pacote, leia esse manual aqui.
Antes de usar o pacote pela primeira vez, digite db basedosdados e confirme novamente se as etapas acima foram concluídas com sucesso.
Como usar
Sintaxe
Antes de mais nada, é importante ter em mãos os comandos possíveis na utilização do pacote. Neste caso, são 7 comandos, com diferentes funcionalidades. Veja na imagem:
| Comando | Descrição |
|---|---|
bd_download | baixa dados da Base dos Dados (BD). |
bd_read_sql | baixa tabelas da BD usando consultas específicas. |
bd_read_table | baixa tabelas da BD usando dataset_id e table_id. |
bd_list_datasets | lista o dataset_id dos conjuntos de dados disponíveis em query_project_id. |
bd_list_dataset_tables | lista table_id para tabelas disponíveis no dataset_id especificado. |
bd_get_table_description | mostra a descrição completa da tabela BD. |
bd_get_table_columns | mostra os nomes, tipos e descrições das colunas na tabela especificada. |
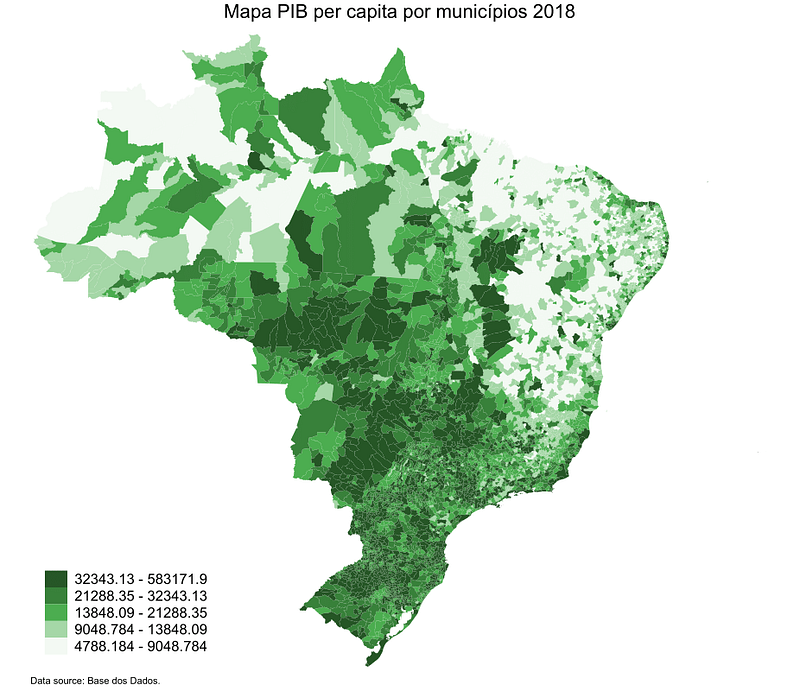
Exemplo de análise: PIB per capita dos municípios brasileiros
- Baixando os dados de PIB e população
Após baixar o pacote conforme as instruções acima, podemos seguir para um exemplo prático a partir do PIB per capita dos municípios brasileiros em 2018. Comece baixando os dados através do comando bd_read_sql:
Observe que na opção path você colocará o local da pasta e nome do arquivo csv que você deseja baixar. Na opção “query” você escreve o comando SQL, assim como faria no próprio Big Query. Nesse caso específico, nossa consulta SQL pega os dados do PIB por município e os dados da população por município e divide um pelo outro, nos fornecendo o PIB per capita, nomeado pela variável pib_pc. Na opção billing_project_id você coloca o id do seu projeto no Google Cloud.
Esses passos te retornarão um arquivo em excel com uma coluna com nome e código dos municípios e o PIB per capita de cada um. Após salvar o arquivo, vamos para o próximo passo de plotar esses dados em um mapa.
- Plotando os dados em um mapa
Para fazer isso, você precisará de arquivos básicos para a plotagem do mapa, associados ao shapefile, obtidos do endereço eletrônico do IBGE Vá na pasta organizacao_do_territorio > malhas_territoriais > malhas_municipais e faça o download do arquivo compactado (formato zip). Para os passos seguintes, você precisará utilizar os arquivos shp, shx, e dbf, disponíveis nesta pasta através do pacote shp2dta no Stata. Não nos alongaremos no uso deste pacote pois não é o foco principal deste texto. Porém, você pode encontrar um ótimo tutorial sobre aqui.
Após seguir o tutorial acima, abra o arquivo com os dados do mapa:
use dadosmapa/brasildata.dta, clear
Renomeie o código do município para id_municipio e faça merge com o arquivo temporário que salvamos acima do PIB per capita:
Baixe o pacote spmap e plote o mapa a partir do seguinte comando:
Nosso projeto já te ajudou de alguma forma? Saiba como nos ajudar:
- Apoie o projeto
- Seja um(a) colaborador(a) de dados na BD
- Colabore com nossos pacotes
- Compartilhe nas redes sociais!
Notou algo errado ou tem uma sugestão?
Contribua com a BD editando este artigo via pull request no nosso GitHub.Base dos Dados