Analisando a frota brasileira com a BD
Saiba quais são as cidades com mais carros por habitantes no Brasil

TL;DR
Neste artigo você irá aprender usar a Base dos Dados para analisar de maneira mais prática os dados de estatísticas da frota de veículos no Brasil (Denatran) e dados da população brasileira (IBGE) em R. Estes dois conjuntos de dados já estão tratados, compatibilizados e prontos para análise no datalake público da BD.
Ao longo do artigo iremos responder 2 perguntas:
- Qual cidade brasileira com mais carros por habitante?
- Como é o share de veículos, entre motos, carros e caminhonetes, das 10 cidades mais populosas do Brasil?
Contexto

Nós os amando ou odiando, os veículos já rodam em terras tupiniquins há mais de 100 anos. Hoje entendemos que uma grande e crescente frota de veículos, aliada a um mau planejamento, pode resultar em congestionamentos, acidentes e poluição atmosférica. Sabemos também que o transporte público e os veículos particulares devem se complementar e que ambos são essenciais para a nossa locomoção.
Dados de Frota de Veículos no Brasil
A Base dos Dados disponibiliza dados de 2003 até 2021, com estatísticas da Frota de veículos por tipo, estado e município. Você pode conferir detalhes desse conjunto e acessá-lo por aqui.
Acessando os dados
Com a facilidade que a BD proporciona, já podemos cruzar as tabelas do IBGE e do Denatran com uma query no R. Conforme aimagem abaixo:
# Pacotes utilizados
library("dplyr")
library("ggplot2")
library("basedosdados")
library("tidyr")
# Defina o seu projeto no Google Cloud
set_billing_id(“xxxx-2609”)
# Para carregar os dados direto no R
query <- "
SELECT
A.automovel,
A.caminhao,
A.caminhonete,
A.camioneta,
A.motocicleta,
A.total,
B.populacao,
C.nome
FROM
`basedosdados.br_denatran_frota.municipio_tipo` A
LEFT JOIN
`basedosdados.br_ibge_populacao.municipio` B
ON
A.ID_MUNICIPIO=b.id_municipio
AND b.ano=2021
LEFT JOIN
`basedosdados.br_bd_diretorios_brasil.municipio` C
ON
A.ID_municipio=c.id_municipio
WHERE
a.ano=2021
AND a.mes=3
"
df <- read_sql(query)
OBS: Para fazer a mudança de id_município para o nome próprio das cidades, foi necessário cruzar com a tabela de diretórios brasileiros da BD, que funciona como uma referência de centralização de informações de unidades básicas para análises.
Respondendo a pergunta: Qual cidade brasileira tem mais carro por habitante?
Após conseguirmos acessar os dados, precisamos fazer pequenas transformações nos mesmos para viabilizar o gráfico e, posteriormente, a própria análise:
# Criando nova coluna com a info de automovel per capita
df$automovel_per_capita <- round(df$automovel / df$populacao, 2)
# Criando um novo dataframe, filtrando cidades com mais de 500 mil habitantes e selecionado o top 10
# do indicador de automovel per capita
df_automovel <- df %>%
filter(populacao >= 500000) %>%
arrange(desc(automovel_per_capita)) %>%
head(10)
df_automovel$nome <- gsub("São Bernardo do Campo", "S.B. do Campo", df_automovel$nome)
#### Gráfico de Automovel por habitante top 10 municipios
black.bold <- element_text(face = "bold", color = "black", size = 15)
ggplot(df_automovel) +
aes(x = reorder(nome, -automovel_per_capita), y = automovel_per_capita) +
geom_col(fill = "#6A51A3") +
geom_text(aes(label = round(automovel_per_capita, 2)), size = 6, vjust = -0.2, colour = "black") +
labs(
x = " ",
y = " ",
title = "Indicador de automóveis per capita por município ",
subtitle = "Top 10 Municípios"
) +
theme_minimal() +
theme(
axis.text.x = black.bold,
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(size = 17)
)
O resultado é o gráfico abaixo, que demonstra os 10 municípios com maior indicador de automóveis per capta no Brasil.
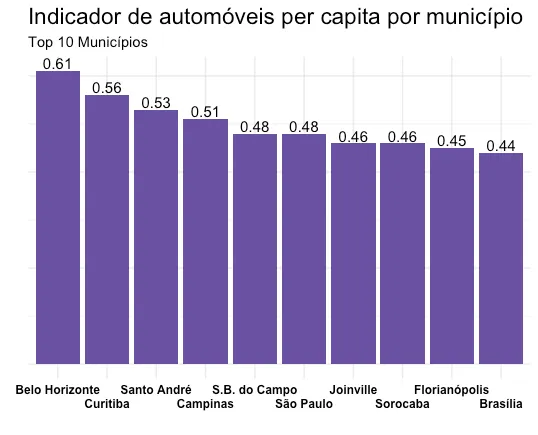
Destaques da análise:
- Belo Horizonte é a cidade do Brasil com a maior quantidade de carros por habitante. Há um carro para cada 0,61 pessoas. (Vale ressaltar que BH provavelmente está na frente dessa lista devido aos descontos tarifários que provém para montadoras e locadoras se instalarem por lá)
- Dentre os municípios dos 10 maiores indicadores calculados, 5 estão no estado de São Paulo, o que nos dá um bom palpite de qual é o estado com mais carros por habitantes.
- 3 cidades da lista foram "planejadas". BH, Brasília e Curitiba são consideradas por muitos como exemplos de cidades que foram planejadas por urbanistas em sua concepção ou posteriormente (caso de Curitiba). De fato, quem já foi a Brasília teve a oportunidade de presenciar como o carro é essencial para tudo por lá.
Respondendo a pergunta: Como é o share entre motos, carros e caminhonetes das 10 cidades mais populosas do Brasil?
Para responder essa pergunta, novamente precisamos fazer algumas transformações nos dados:
#### Analise 2: Shares dos top 10 municipios mais populosos
# filtrando os dados que usaremos
df_share <- df %>%
mutate(caminhonete = caminhonete + camioneta) %>%
arrange(desc(populacao)) %>%
head(10) %>%
select(automovel, motocicleta, caminhonete, nome)
# transformando em tidy para possibilitar fazer o gráfico
df_share_tidy <- df_share %>%
pivot_longer(
-nome,
names_to = "tipo_veiculo",
values_to = "qtd"
)
# adicionando o percent para os labels do gráfico
df_share_total <- df_share_tidy %>%
group_by(nome) %>%
summarise(total = sum(qtd)) %>%
left_join(df_share_tidy, by = "nome") %>%
mutate(percent = round(qtd / total, 2))
df_share_total$tipo_veiculo <- as.factor(df_share_total$tipo_veiculo)
#### Gráfico de share de tipo dos veículos top 10 municipios mais populosos
black.bold2 <- element_text(face = "bold", color = "black", size = 8)
ggplot(df_share_total, aes(fill = tipo_veiculo, y = as.numeric(percent), x = nome)) +
geom_bar(position = "fill", stat = "identity") +
geom_text(
aes(label = paste0(percent * 100, "% ")),
position = position_stack(vjust = 0.7),
size = 5
) +
scale_fill_manual(values = c("#DADAEB", "#9E9AC8", "#6A51A3")) +
labs(
x = " ",
y = " ",
title = "Share de veículos",
subtitle = "Top 10 Municípios mais populosos"
) +
theme_minimal() +
theme(
axis.text.y.left = black.bold2,
axis.text.x = element_blank(),
axis.ticks.y = element_blank(),
plot.title = element_text(size = 17)
) +
coord_flip()
O resultado é o gráfico abaixo, que demonstra em porcentagem o share de veículos nos municípios mais populosos do Brasil.
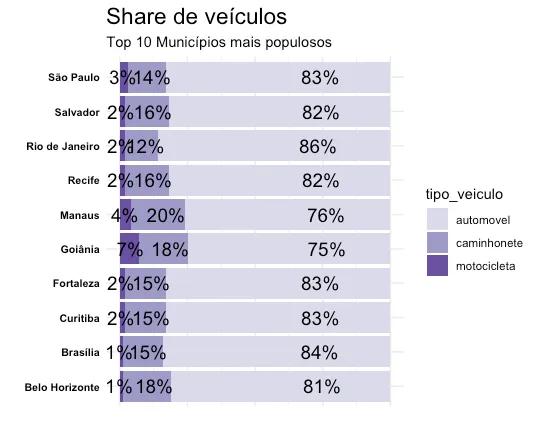
Destaques da análise:
- Goiânia, além de ser uma das cidades do top 10 com maior share de caminhonetes, tem a maior presença das motocicletas em suas ruas (7% do total de veículos).
- São Paulo que seria o meu principal palpite para ter maior share de motocicletas, conta com apenas 3% delas em sua frota, não muito diferente de outras capitais como o RJ (2%) e Manaus (4%).
- Rio de Janeiro tem o maior share de carros em suas ruas (86%), com o menor em caminhonetes (12%). Talvez essa baixa presença de caminhonetes na Cidade Maravilhosa possa ter a ver com o terreno da região restante do estado ou até uma questão de preferência dos consumidores, não é possível dizer ao certo.
Conclusão
Para concluir esse breve artigo, identificamos as 10 cidades com maior taxa de veículos por habitante e vimos que, em média, nessas cidades há um carro a cada duas pessoas (0,5). Esse é um número bem alto, tendo em vista que uma relevante fatia da população não tem condições financeiras para comprar um carro ou nem pode dirigir por questão de idade.
Além disso, na análise do share de veículos das cidades mais populosas, se destacou o fato de Goiânia e Manaus terem um perfil distinto das outras capitais presentes no estudo. Nas outras cidades, os percentuais entre Carros, Motos e Caminhonetes se assemelham bastante, o que também é uma surpresa.
Notou algo errado ou tem uma sugestão?
Contribua com a BD editando este artigo via pull request no nosso GitHub.Base dos Dados